Muyan-TTS
综合介绍
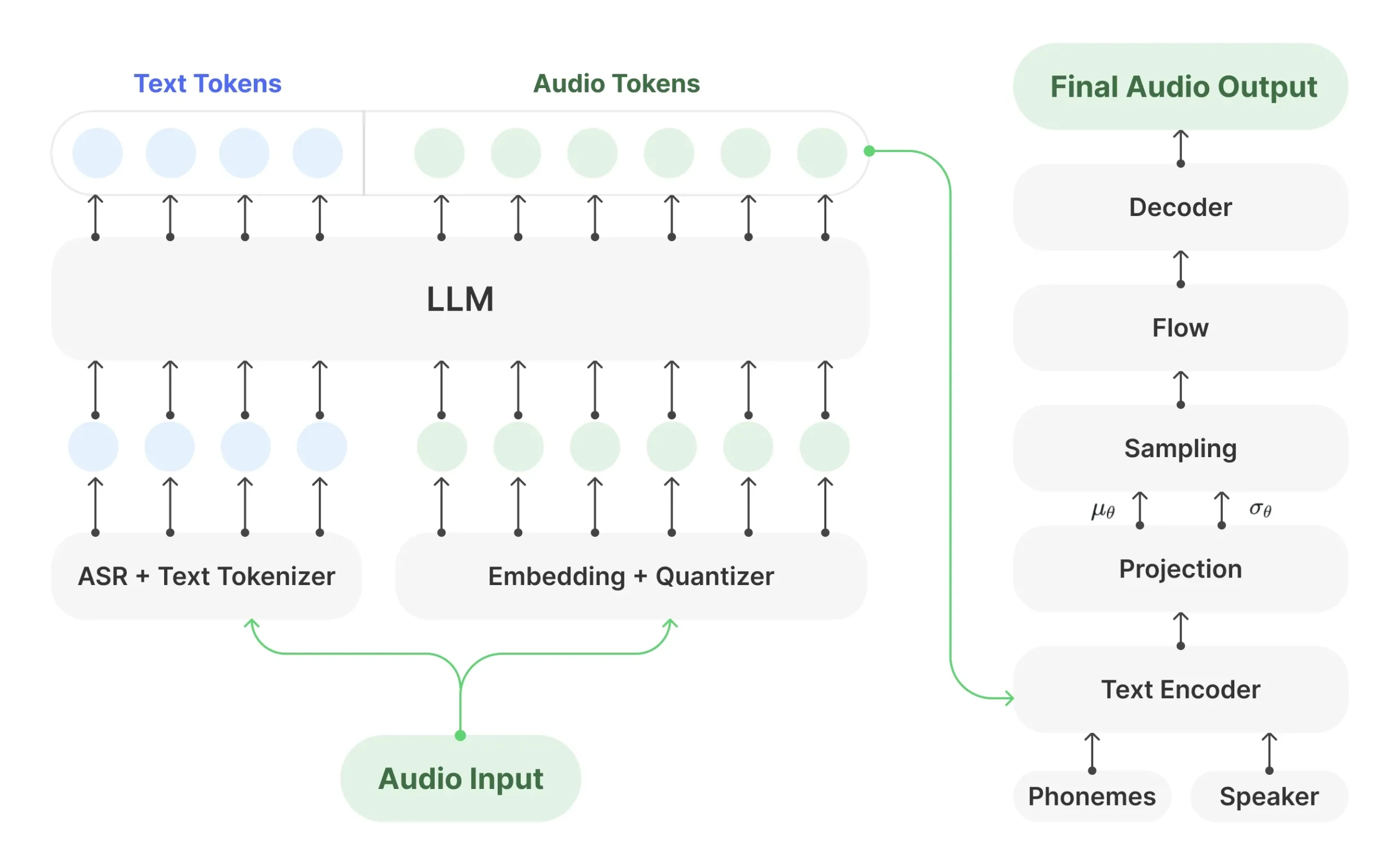
Muyan-TTS 是一个专为播客场景设计的可训练文本转语音(TTS)模型。它在一个庞大的数据集上进行了预训练,该数据集包含超过10万小时的播客音频数据。这使得模型具备了高质量的零样本(zero-shot)语音合成能力,仅需一小段音频样本,就能模仿该声音生成新的语音内容。此外,Muyan-TTS 支持对特定人物的声音进行微调(SFT),用户可以使用目标人物几十Mins的语音数据来训练模型,从而实现声音的高度定制化。该模型的技术架构由一个大型语言模型(LLM)和一个 SoVITS 解码器组成,语言模型负责处理文本和声音的对应关系,解码器则将这些信息转换为最终的音频波形。
功能列表
- 零样本语音合成 (Zero-shot TTS):提供一段参考音频和对应的文本,即可使用该音色合成任意新的英文文本。
- 少样本声音微调 (Few-shot SFT):支持使用目标人物几十Mins的语音数据进行模型微调,以生成高度相似和自然的定制化语音模型。
- API 服务:内置基于 FastAPI 的 API 服务,方便开发者将语音合成功能集成到自己的应用中,并默认启用 vLLM 加速以提升推理性能。
- 播客场景优化:模型在超过10万小时的播客数据上进行训练,特别适合生成长篇音频内容。
- 快速推理:在 NVIDIA A100 GPU 上,生成一秒音频所需的时间约为0.33秒,性能优于多种主流开源TTS模型。
- 开源代码和模型:项目提供了完整的训练和推理代码,以及预训练好的基础模型和微调范例模型,方便用户直接使用或进行二次开发。
使用帮助
Muyan-TTS 的使用主要分为直接推理和模型微调两个部分。无论进行哪种操作,首先都需要完成环境的安装和模型的下载。
1. 安装环境和下载模型
第一步:克隆代码仓库打开终端,使用 git 命令将项目代码克隆到本地。
git clone https://github.com/MYZY-AI/Muyan-TTS.git
第二步:进入项目目录并创建虚拟环境为了避免与系统中其他Python库产生冲突,建议使用 conda 创建一个独立的环境。
cd Muyan-TTS
conda create -n muyan-tts python=3.10 -y
conda activate muyan-tts
第三步:安装依赖项目提供了一个 Makefile 文件来简化安装过程。
make build
此外,系统需要安装 FFmpeg 工具用于音频处理。如果你使用的是 Ubuntu 系统,可以通过以下命令安装:
sudo apt update
sudo apt install ffmpeg
第四步:下载预训练模型你需要下载项目所需的多个模型文件:
- Muyan-TTS (基础模型):用于零样本推理。可以从 huggingface, modelscope 或 wisemodel 下载。
- Muyan-TTS-SFT (微调模型):这是一个官方提供的微调范例模型,用于展示少样本微调的效果。下载地址同上。
- chinese-hubert-base:这是语音识别和处理相关的前置模型。
下载完成后,在项目根目录下创建一个名为 pretrained_models 的文件夹,并将所有下载好的模型文件放入其中。最终的目录结构应如下所示:
pretrained_models/
├── chinese-hubert-base/
├── Muyan-TTS/
└── Muyan-TTS-SFT/```
### 2. 快速上手:进行语音合成
Muyan-TTS 提供了两种方式进行语音合成:命令行脚本和 API 服务。
**方式一:使用 `tts.py` 脚本直接合成**
这是一个简单直接的推理方式。打开 `tts.py` 文件,你可以看到核心的调用逻辑。你主要需要关注和修改以下三个参数:
- `ref_wav_path`: 参考音频的路径。这段音频是你想要模仿的音色。
- `prompt_text`: 参考音频对应的文本内容。
- `text`: 你希望模型合成的新文本内容。
运行以下命令启动合成:
```bash
python tts.py
```合成完成后,默认的输出文件会保存在 `logs/tts.wav`。
**使用不同模型进行合成:**
- **零样本合成(使用基础模型)**:
在 `tts.py` 中,将 `model_type` 参数设置为 `'base'`。你可以将 `ref_wav_path` 更换为任意一段清晰的英文音频,并提供对应的 `prompt_text`,模型就会模仿该音色来朗读 `text` 的内容。
- **使用微调模型合成**:
在 `tts.py` 中,将 `model_type` 参数设置为 `'sft'`。此时,你必须使用官方提供的参考音频(`assets/Claire.wav`),因为这个SFT模型是基于该音色训练的。
**方式二:使用 `api.py` 启动服务**
对于需要将 TTS 功能集成的开发者来说,API 是更灵活的方式。该模式会自动启用 vLLM 加速,以获得更快的推理速度。
**启动服务:**
```bash
python api.py
默认情况下,服务会在 8020 端口启动。你可以通过传递 model_type 参数(base 或 sft)来指定加载哪个模型。
调用 API:你可以使用任何编程语言或工具向该服务发送 POST 请求。以下是一个 Python 示例:
import time
import requests
TTS_PORT = 8020
payload = {
"ref_wav_path": "assets/Claire.wav",
"prompt_text": "Although the campaign was not a complete success, it did provide Napoleon with valuable experience and prestige.",
"text": "Welcome to the captivating world of podcasts, let's embark on this exciting journey together.",
"temperature": 1.0,
"speed": 1.0,
}
start = time.time()
url = f"http://localhost:{TTS_PORT}/get_tts"
response = requests.post(url, json=payload)
# 将返回的音频流写入文件
audio_file_path = "logs/api_tts.wav"
with open(audio_file_path, "wb") as f:
f.write(response.content)
print(f"API call finished in {time.time() - start} seconds.")
print(f"Audio saved to {audio_file_path}")
将以上代码保存为 test_api.py 并运行,即可调用服务生成音频。
3. 如何训练你自己的声音模型
Muyan-TTS 的一大特色是支持用户对自己或他人的声音进行微调。
第一步:准备数据集你需要准备目标人物至少十几Mins的清晰语音,以及每段语音对应的文本。将数据整理成项目要求的格式,可以参考 data_process/examples 中的示例。
第二步:运行训练脚本项目提供了一个总括性的训练脚本 train.sh。这个脚本会自动完成数据处理和模型训练的全过程。在运行前,你需要修改 prepare_sft_dataset.py 文件,将其中的 librispeech_dir 变量指向你自己的数据集所在的路径。
然后,在终端执行:
./train.sh```
脚本会自动处理数据,生成 `data/tts_sft_data.json`,并调用 `llamafactory-cli` 开始训练。训练的详细配置(如学习率、训练轮次等)可以在 `training/sft.yaml` 文件中进行调整。
**第三步:使用训练好的新模型**
训练完成后,新的模型权重默认保存在 `pretrained_models/Muyan-TTS-new-SFT` 目录下。
在使用这个新模型进行推理之前,你需要将基础模型中的 `sovits.pth` 文件复制到新模型目录中:
```bash
cp pretrained_models/Muyan-TTS/sovits.pth pretrained_models/Muyan-TTS-new-SFT/
现在,你就可以通过 tts.py 或 api.py 来调用你的专属声音模型了。记得在调用时,将 model_type 指定为 sft,并将 model_path 指向你的新模型目录。同时,ref_wav_path 和 prompt_text 也要换成你训练时使用的那个人物的语音和文本样本。
应用场景
- 播客和有声书制作利用其对长文本和高质量语音的优化,可以快速、低成本地将文字内容转换为听起来自然的音频节目。创作者可以克隆自己的声音,实现节目的自动化生产。
- 个性化语音助手开发者可以将 Muyan-TTS 集成到智能应用中,通过微调生成特定角色的声音,为用户提供独特的语音交互体验,例如在游戏或虚拟助手应用中创建专属的 NPC 声音。
- 内容创作和数字人视频创作者或虚拟主播可以使用该工具为自己的数字形象生成配音,无需本人反复录制。只需提供一段参考音频,即可生成任意台词,大大提升内容生产效率。
- 教育和培训材料将在线课程、培训文档等材料转换为音频格式,方便学习者在通勤或运动等场景下进行学习。可以为不同的课程定制不同的讲解员声音。
QA
- Muyan-TTS 支持中文吗?不支持。根据官方说明,由于模型的训练数据绝大部分是英文播客,目前仅支持英文输入。
- 什么是零样本(Zero-shot)TTS?零样本TTS指的是模型在没有经过特定说话人声音训练的情况下,仅通过一段该说话人简短的音频(例如几秒钟),就能模仿其音色、韵律和风格来合成新的语音。
- 训练自己的声音模型需要多好的显卡?官方文档提到其训练成本是基于 NVIDIA A100 和 A10 GPU 计算的,这表明微调过程需要强大的计算资源。虽然没有给出最低配置要求,但通常这类模型的微调至少需要显存较大的专业级或高端消费级显卡(如 RTX 3090/4090)。
- API 模式下的
vLLM加速是什么?vLLM 是一个用于提升大型语言模型(LLM)推理速度和吞吐量的开源库。Muyan-TTS 的 API 模式集成了 vLLM,通过优化内存管理和并行处理,使其在处理语音生成请求时响应更快、效率更高。 - 模型和 GPT-SoVITS 有什么关系?官方在文档中承认借鉴了 GPT-SoVITS 项目的大量代码。可以将 Muyan-TTS 理解为在 GPT-SoVITS 的思路上,使用了更适合播客场景的数据(超过10万小时)、更强大的基础模型(Llama-3.2-3B),并针对性地优化了训练流程和成本的特定领域版本。